7 Classification II
This section will extend on classification algorithms in GEE from last chapter. Focusing on sub-pixel analysis anmd object-based analysis, the following will continue using Shenzhen, China as the study area.
7.1 Summary
7.1.1 Sub Pixel Analysis
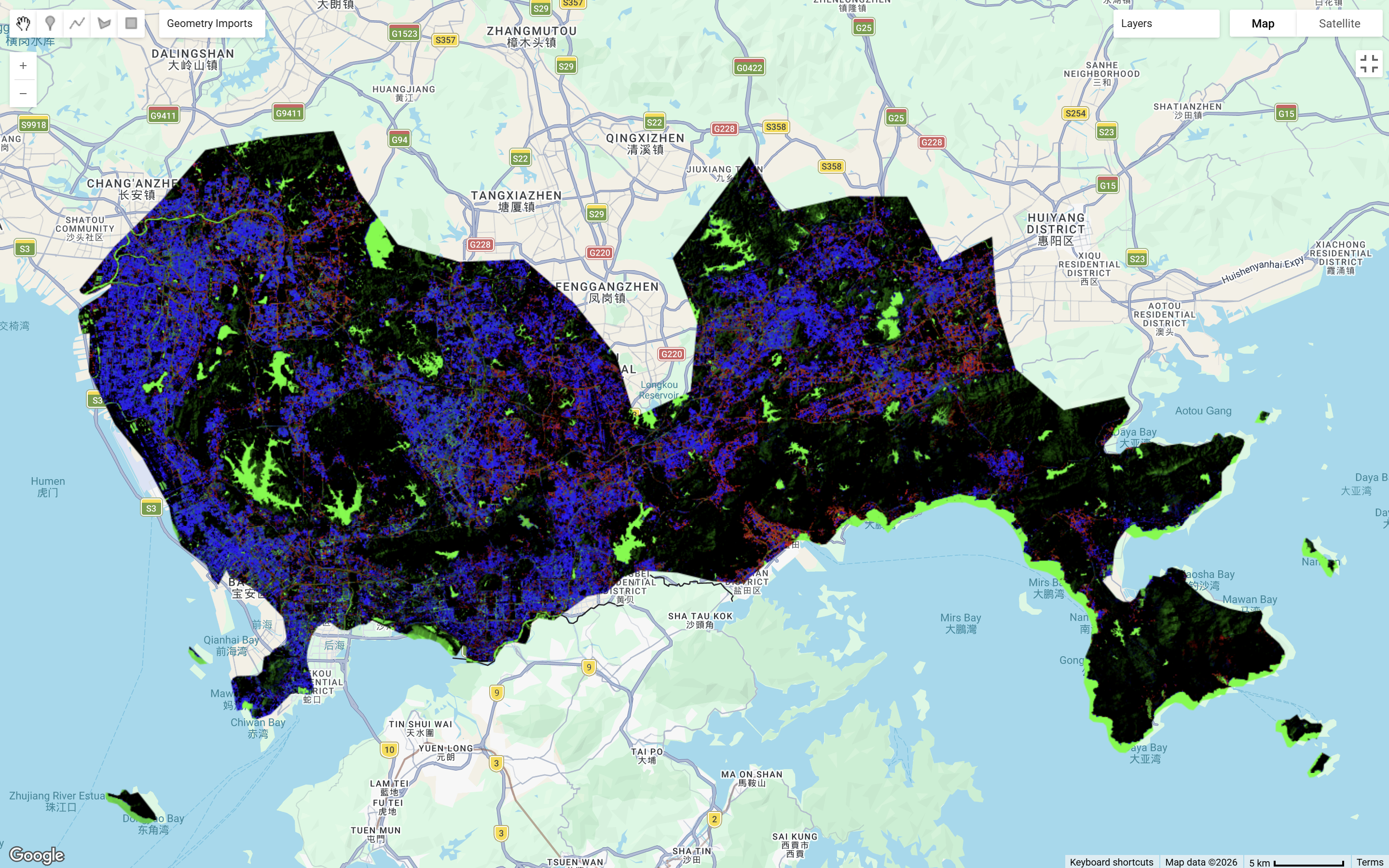
What I found most useful this week was learning that pixel-based classification methods can struggle in urban environments. In a city like Shenzhen, land cover is highly spatially heterogeneous and many neighboring surfaces are spectrally similar. With Landsat’s 30 m spatial resolution, individual pixels often contain mixtures of surfaces such as buildings, roads, and vegetation, which can lead to overestimation of urban land uses (MacLachlan et al. 2017). This made sub-pixel analysis particularly interesting, because instead of classifying each pixel into one class, it is able to estimate the fractional composition of land cover within each pixel (Ge et al. 2014). This is especially useful in urban areas, where mixed pixels are unavoidable. Despite, it poses limitations. Although sub-pixel analysis provides a finer representation of land cover, the output can look noisy and harder to interpret, and some of its advantages may be reduced once fractions are hardened into discrete classes. The below shows Shenzhen under sub-pixel analysis:
7.1.2 Object-Based Image Analysis (OBIA)
OBIA approaches classification differently by grouping neighboring pixels as objects rather than treating each pixel independently. Segmentation methods such as K-means and SNIC showed how classification can incorporate not only spectral information but also spatial and contextual characteristics. SNIC is comparatively more effective as it is computationally efficient and reduces noise through averaging spectral values, yet its performance depends strongly on segmentation parameters such as compactness, connectivity and neighborhoodSize(Matarira et al. 2023). What stood out is that OBIA improves the representation of spatial heterogeneity, however it does not correct resolution biases. This is important to awknowledge as method choice can improve classification, there is no method that can completely remove heterogeneity.
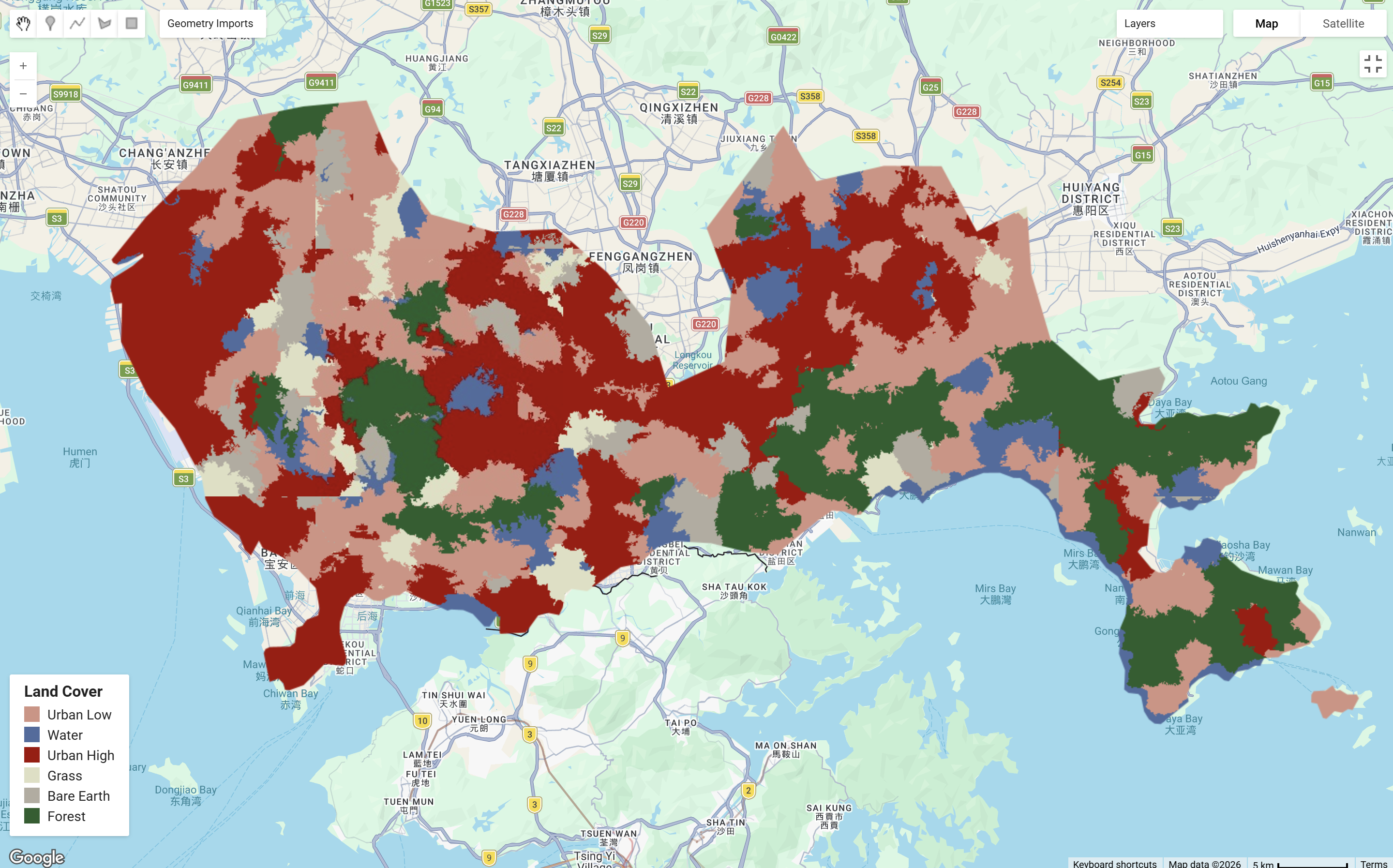
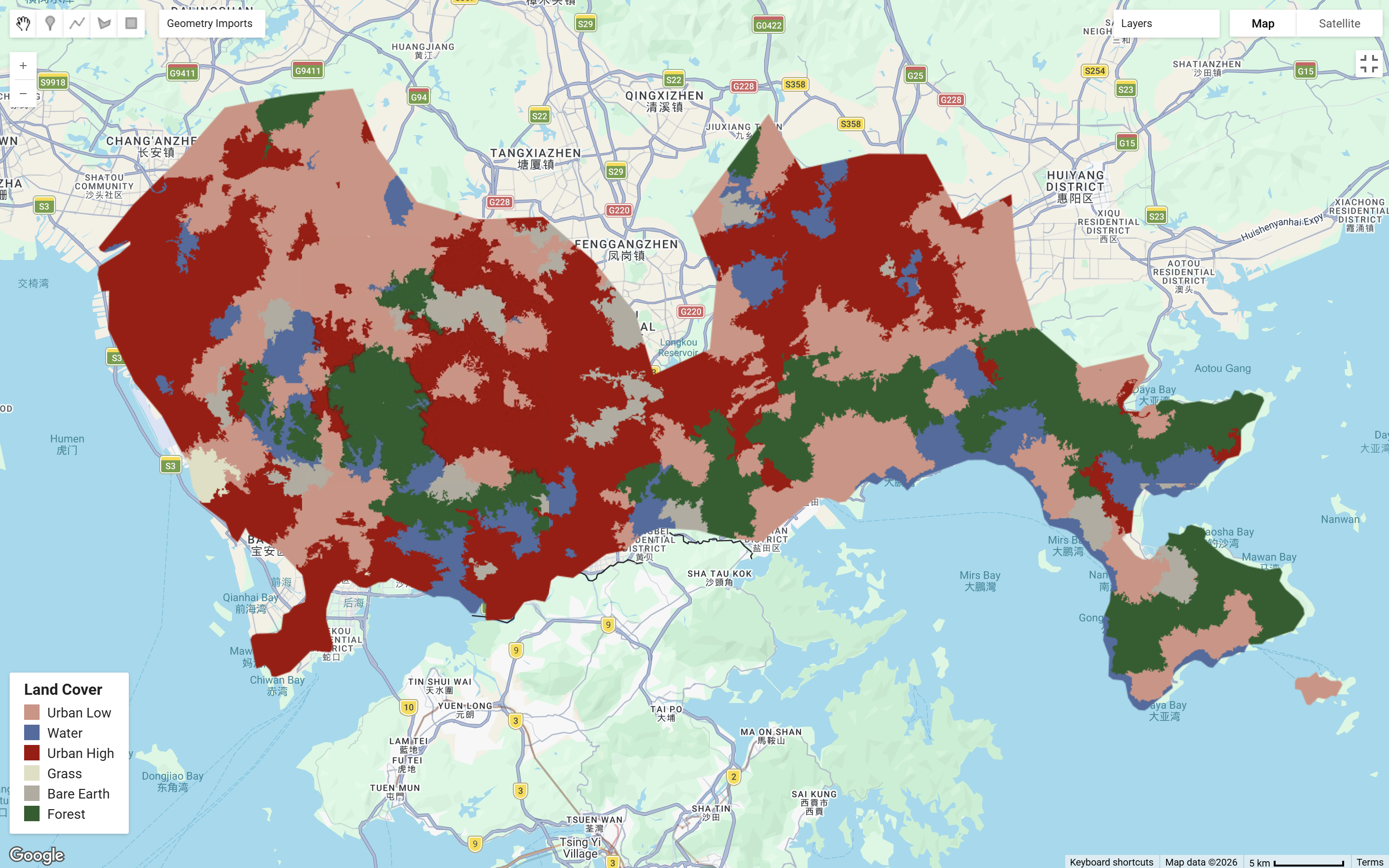
The below shows Shenzhen under neighborhoodSize values of 50 and 256. The neighbourhood size controls the scale which pixels are groupped into objects in classification. A smaller neighborhood size can preserve finer details, whereas a larger neighborhood size will show borader clustering:
| Method | Strengths | Limitations | When to use? |
|---|---|---|---|
| Sub-pixel Analysis |
|
|
|
| Object-based Image Analysis |
|
|
|
7.1.3 Accuracy Assessment
The purpose of accuracy assessment is to estimate the error and uncertainty of classification. Resampling procedures such as bootstrapping and cross-validation can be used to estimate map accuracy and associated uncertainty (Lyons et al. 2018).
Precision: Also known as the user’s accuracy \(\frac{\text{TP}}{\text{TP} + \text{FP}}\), it refers to the proportion of pixels that is classified a class that is actually correct and represents the ground truth.
Recall: Also known as the producer’s accuracy \(\frac{\text{TP}}{\text{TP} + \text{FT}}\), it refers to the proportion of pixels that the classification are representing that class in reality.
Overall Accuracy: Trade-off between Precision and Recall, they can never be both good as our data is often imbalanced.
F1 score: The harmonic mean between precision and recall, ranging from 0 to 1 (closer to 1 indicates better performance)
Note that accuracy assessment do not account for spatial autocorrelation!! Achieving a higher overall accuracy score does not always mean that the classification model is better…
A workflow I will adopt:
Class Definition → Pre-processing → Spatial Cross Validation (or Train Test Split) → Pixel Assignment (Sub-pixel ; OBIA) → Accuracy Assessment
For now, I am leaning more towards Spatial Cross Validation, because spatial classification seems more likely to provide a more realistic estimate than a simple random train-test split.
GEE code for this practical can be found here.
More on Accuracy Assessment can be found here.
7.2 Applications
7.2.1 Approaches
Sub-pixel analysis and OBIA have been applied across a range of land cover and monitoring contexts, yet the choice of methods tends to depend on spatial resolution of available imagery. Literature shows that object-based image analysis is often used for understanding urban form in a way that is more meaningful than pixel-by-pixel land-cover labels. Geographic Object-Based Image Analysis (GEOBIA) workflow in GEE has been used to identify informal settlements by integrating Sentinel-1, Sentinel-2 and PlanetScope imagery, showing how texture and object-based spatial context can improve the identification of morphologically complex settlement patterns (Matarira et al. 2023). This makes OBIA especially useful to understand the spatial pattern and structure of urban areas beyond pure land cover. Similarly, Ma et al. (2021) showed that object-based approaches can support the classification of urban surface structure and cover, while also capturing more detailed internal spatial structure even when overall classification accuracy (OA) is not as high.
Sub-pixel methods are applied more often for needs to estimate endmember proportions or fractional surface cover through time series. Zhang, Zhang, and Wang (2023) developed a seasonal approach for monitoring sub pixel impervious surface dynamics with Landsat 8, which is useful as urban change often happens gradually over time. This makes sub-pixel analysis a more sensible approach when estimating a fractional surface proportion rather than assign each pixel to a fixed class. Similarly, Li et al. (2023) also showed that extracting sub pixel vegetation NDVI time series in urban areas can change estimates of vegetation productivity, suggesting that these fractional approaches does not only influences land cover classification but also the environmental indicators derived from it.
So, the key takeaway from the literature is that OBIA is more useful when spatial pattern, morphology, and finer spatial resolution matter (especially under urban contexts), while sub-pixel approaches are more useful to estimate vegetation or impervious endmembers fractions from mixed pixels in medium spatial resolution imagery over time.
7.2.2 GEE Pre-classified Products
Taking it further, there are publicly available pre-classified products that are easily accessible through the Earth Engine Data Catalog. For land use and land cover change analysis, Dynamic World V1 and ESA WorldCover 10 m v200 can be used for land classifiers. The Global Map of Local Climate Zones (LCZ) adds a different perspective by classifying areas according to urban form and surface structure, which makes it more useful for analysing neighbourhood types, urban morphology and urban climate patterns than simple land cover. Beyond these, GEE also includes building datasets such as Open Buildings V3 Polygons for building level analysis across regions and TIGER: US Census Roads for road data but limited to the US.
7.3 Reflection
This week made me think much more about what classification is actually claiming to represent. Both sub-pixel analysis and OBIA address some of the limits of pixel-based classification, but they doesn’t fully resolve spatial heterogeneity. This also highlighted the importance of considering spatial autocorrelation in classification. Since nearby pixels are often similar, accuracy can be overestimated if this is not taken into account.
Personally, I think this week will be useful for me in future work because it made me more aware that classification is not just a technical workflow in GEE, but a set of choices with consequences for interpretation, comparison and decision-making. The part I will keep in mind is that accuracy is not only about getting a high score, but about making sure the method matches the spatial reality.